
SQL — одна из частых тем на техническом интервью для аналитиков, разработчиков и архитекторов. Задачи кажутся простыми, но именно здесь легко разволноваться и не выполнить задание. В этом посте разберём путь от базового SELECT до уверенного применения JOIN и HAVING — с задачами, которые реально давали на собеседованиях.
В теле поста краткое описание теории и задачи, в самом конце ответы.
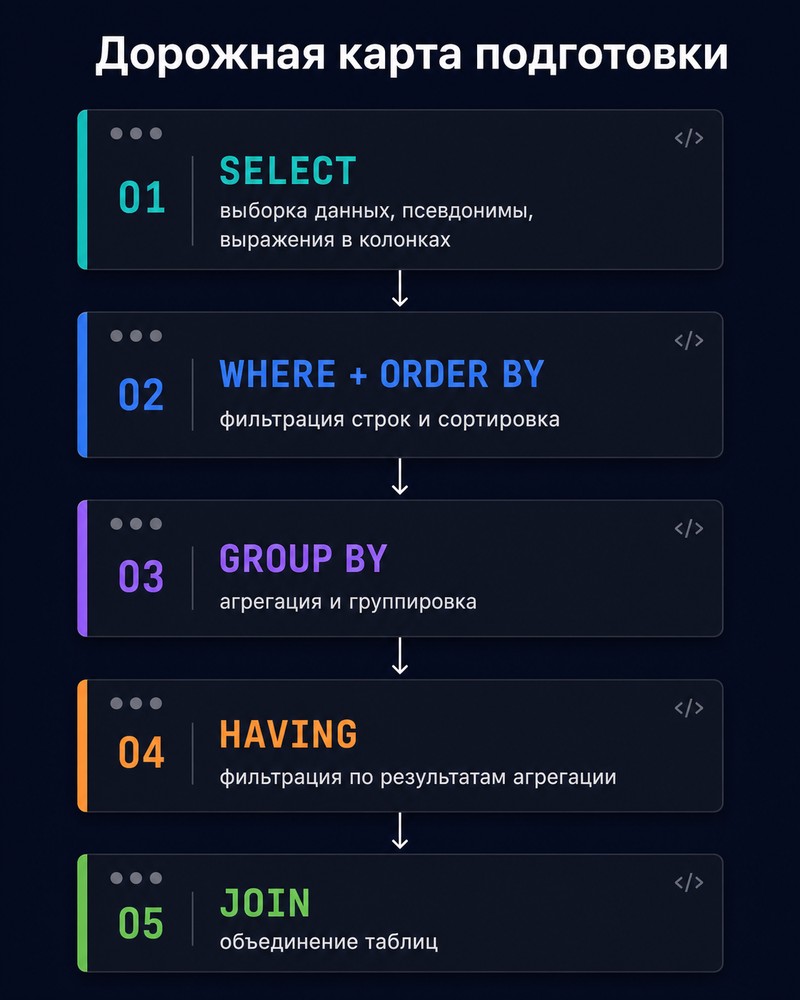
Дорожная карта подготовки
Изучай темы именно в этом порядке — каждая следующая строится на предыдущей:
- SELECT — выборка данных, псевдонимы, выражения в колонках
- WHERE + ORDER BY — фильтрация строк и сортировка
- GROUP BY — агрегация и группировка
- HAVING — фильтрация по результатам агрегации
- JOIN — объединение таблиц
SELECT и WHERE
SELECT определяет, что вернуть. WHERE — какие строки оставить. Это фундамент, без этих операторов блок SQL на собеседовании не пройти.
Задача 1. Есть таблица employees. Выведи имена и зарплаты сотрудников из отдела 'Engineering', у которых зарплата выше 80 000. Отсортируй по зарплате по убыванию.
-- Создание таблицы
CREATE TABLE employees (
id INT PRIMARY KEY,
name VARCHAR(100),
dept VARCHAR(50),
salary DECIMAL(10,2),
hired_at DATE
);
-- Тестовые данные
INSERT INTO employees (id, name, dept, salary, hired_at) VALUES
(1, 'Алексей Громов', 'Engineering', 95000.00, '2021-03-15'),
(2, 'Мария Соколова', 'Engineering', 78000.00, '2022-07-01'),
(3, 'Иван Петров', 'Engineering', 112000.00,'2019-11-20'),
(4, 'Ольга Белова', 'Marketing', 65000.00, '2020-05-10'),
(5, 'Дмитрий Козлов', 'Engineering', 80500.00, '2023-01-12'),
(6, 'Анна Лебедева', 'HR', 58000.00, '2021-08-30'),
(7, 'Сергей Новиков', 'Engineering', 74000.00, '2022-04-18'),
(8, 'Екатерина Зайцева', 'Marketing', 71000.00, '2020-12-05');
Ожидаемый результат: 3 строки — Алексей Громов (95000), Дмитрий Козлов (80500), Иван Петров (112000), отсортированные по убыванию зарплаты.
GROUP BY
GROUP BY разбивает строки на группы по значению поля. Агрегатные функции — COUNT, SUM, AVG, MIN, MAX — вычисляют одно значение для каждой группы.
Задача 2. Есть таблица customers. Найди количество уникальных городов в каждой стране.
-- Создание таблицы
CREATE TABLE customers (
id INT PRIMARY KEY,
name VARCHAR(100),
country VARCHAR(50),
city VARCHAR(50)
);
-- Тестовые данные
INSERT INTO customers (id, name, country, city) VALUES
(1, 'Иван Иванов', 'Россия', 'Москва'),
(2, 'Петр Петров', 'Россия', 'Сочи'),
(3, 'Сергей Сергеев', 'Беларусь', 'Минск'),
(4, 'Алексей Алексеев', 'Беларусь', 'Витебск'),
(5, 'Дмитрий Дмитриев', 'Россия', 'Сочи'),
(6, 'Василий Васильев', 'Россия', 'Пермь'),
(7, 'Николай Николаев', 'Беларусь', 'Минск'),
(8, 'Александр Смирнов','Россия', 'Москва'),
(9, 'Михаил Михайлов', 'Беларусь', 'Гродно'),
(10, 'Игорь Игорев', 'Беларусь', 'Гомель');
COUNT(*)считает строки,COUNT(DISTINCT city)— уникальные значения. Важно показать понимание разницы во время технического интервью
Ожидаемый результат: Россия — 3 уникальных города (Москва, Сочи, Пермь), Беларусь — 4 (Минск, Витебск, Гродно, Гомель).
HAVING
WHERE фильтрует строки до группировки. HAVING — после. Часто задания строят так что бы подловить кандидата с этими операторами.
Нельзя написать WHERE COUNT(*) > 2 — получишь ошибку. Только HAVING COUNT(*) > 2.
Задача 3. Есть таблица orders. Найди клиентов, у которых суммарная сумма заказов превышает 5000. Выведи customer_id и суммарную сумму.
-- Создание таблицы
CREATE TABLE orders (
id INT PRIMARY KEY,
customer_id INT,
amount DECIMAL(10,2),
order_date DATE
);
-- Тестовые данные
INSERT INTO orders (id, customer_id, amount, order_date) VALUES
(1, 1, 1200.00, '2024-01-05'),
(2, 1, 3500.00, '2024-02-10'),
(3, 2, 800.00, '2024-01-15'),
(4, 2, 950.00, '2024-03-01'),
(5, 3, 4200.00, '2024-01-20'),
(6, 3, 1800.00, '2024-02-28'),
(7, 4, 300.00, '2024-03-10'),
(8, 4, 450.00, '2024-03-15'),
(9, 5, 6100.00, '2024-02-05'),
(10, 5, 200.00, '2024-03-20');
Запомни логический порядок выполнения запроса:
FROM → JOIN → WHERE → GROUP BY → HAVING → SELECT → ORDER BY → LIMIT
Ожидаемый результат: customer_id 1 (4700), customer_id 3 (6000), customer_id 5 (6300).
JOIN
Реальные данные разложены по таблицам. JOIN связывает их по ключу.
| Тип | Что возвращает |
|---|---|
INNER JOIN | Только совпадающие строки в обеих таблицах |
LEFT JOIN | Все строки из левой + совпадения из правой (NULL если нет пары) |
RIGHT JOIN | Все строки из правой + совпадения из левой |
FULL OUTER JOIN | Все строки из обеих таблиц |
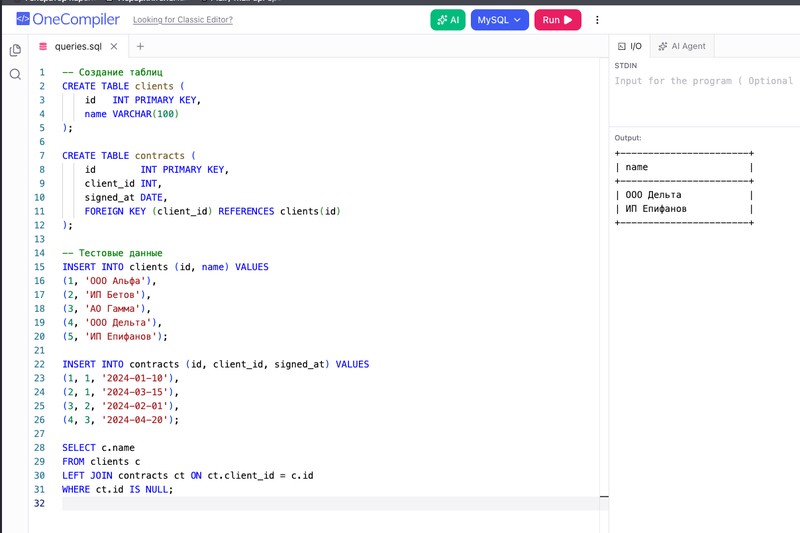
Задача 4. Есть таблицы clients и contracts. Выведи клиентов, у которых нет ни одного контракта.
-- Создание таблиц
CREATE TABLE clients (
id INT PRIMARY KEY,
name VARCHAR(100)
);
CREATE TABLE contracts (
id INT PRIMARY KEY,
client_id INT,
signed_at DATE,
FOREIGN KEY (client_id) REFERENCES clients(id)
);
-- Тестовые данные
INSERT INTO clients (id, name) VALUES
(1, 'ООО Альфа'),
(2, 'ИП Бетов'),
(3, 'АО Гамма'),
(4, 'ООО Дельта'),
(5, 'ИП Епифанов');
INSERT INTO contracts (id, client_id, signed_at) VALUES
(1, 1, '2024-01-10'),
(2, 1, '2024-03-15'),
(3, 2, '2024-02-01'),
(4, 3, '2024-04-20');
Ожидаемый результат: ООО Дельта и ИП Епифанов — клиенты без контрактов.
Всё вместе: JOIN + GROUP BY + HAVING
На интервью любят задачи, где нужно соединить сразу несколько приёмов.
Задача 5. Те же таблицы clients и contracts. Найди клиентов, у которых более одного контракта. Выведи имя клиента и количество контрактов.
Данные те же, что в Задаче 4 — создавать повторно не нужно.
Ожидаемый результат: ООО Альфа — 2 контракта.
Где тренироваться
OneCompiler — онлайн-песочница, поддерживает MySQL, PostgreSQL, SQLite. Вставляй DDL из задачи и сразу проверяй запрос. Регистрация не нужна.
Codewars — SQL kata — 400+ задач с автопроверкой, от простых SELECT до сложных соединений и вложенных запросов. Хорошо подходит для системной прокачки даже с нуля.
Ответы
Задача 1 — SELECT + WHERE
SELECT name, salary
FROM employees
WHERE dept = 'Engineering'
AND salary > 80000
ORDER BY salary DESC;
Задача 2 — GROUP BY + COUNT DISTINCT
SELECT
country,
COUNT(DISTINCT city) AS unique_cities
FROM customers
GROUP BY country
HAVING COUNT(*) > 1;
Задача 3 — GROUP BY + HAVING
SELECT
customer_id,
SUM(amount) AS total_amount
FROM orders
GROUP BY customer_id
HAVING SUM(amount) > 5000;
Задача 4 — LEFT JOIN + IS NULL
SELECT c.name
FROM clients c
LEFT JOIN contracts ct ON ct.client_id = c.id
WHERE ct.id IS NULL;
Задача 5 — JOIN + GROUP BY + HAVING
SELECT
c.name,
COUNT(ct.id) AS contract_count
FROM clients c
JOIN contracts ct ON ct.client_id = c.id
GROUP BY c.id, c.name
HAVING COUNT(ct.id) > 2;
Это третий пост из серии #ГотовимсяКСобеседованию. В следующих выпусках — разберем ещё больше тем для системного аналитика и архитектора.