Зачем системному аналитику знать об индексах
На технических собеседованиях в зрелые продуктовые компании и ИТ-холдинги вопросы про индексы задают регулярно — и не только DBA. Системный аналитик, архитектор и даже старший бизнес-аналитик должен уметь объяснить, почему на определённом запросе «всё лагает», и предложить решение. Именно здесь индексы — первый и самый частый ответ.
Блок про индексы обычно идет после общего блока про базы данных и до блока с написанием SQL запросов.
Понимание индексов нужно на практике при:
- Проектировании новых таблиц и согласовании физической модели данных с разработчиками и DBA
- Анализе производительности запросов при интеграции систем и проектировании витрин
- Оценке архитектурных компромиссов между скоростью чтения и стоимостью записи при высоконагруженных сценариях
Что такое индекс — за 30 секунд
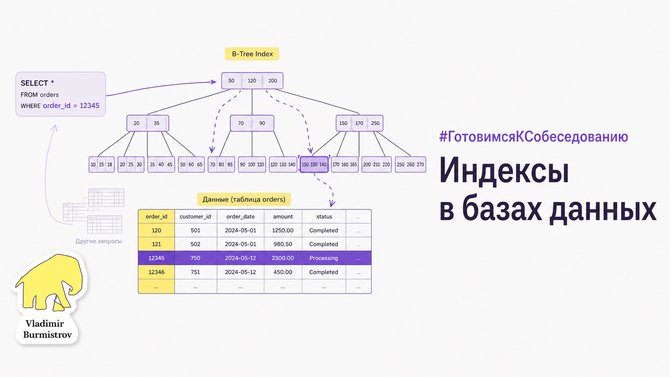
Индекс — это отдельная структура данных, которая хранит упорядоченные значения одного или нескольких столбцов таблицы вместе со ссылкой на строку в исходной таблице. По сути это «содержание книги», вместо перечитывания всей книги целиком вы ищете нужное слово в алфавитном списке и сразу переходите на нужную страницу.
Без индекса база данных вынуждена делать full table scan — читать каждую строку таблицы. С индексом запрос обходит структуру (обычно B-дерево) за (O(\log n)) операций вместо (O(n)).
Главный компромисс: индексы ускоряют чтение (SELECT), но замедляют запись (INSERT / UPDATE / DELETE) — при каждом изменении данных база должна обновить и сам индекс.
Типы индексов
Разные задачи требуют разных структур. Ниже — основная классификация, которую стоит повторить перед собеседованием.
По физическому хранению данных
| Тип | Ключевая особенность | Когда использовать |
|---|---|---|
| Кластерный (Clustered) | Физически переупорядочивает строки таблицы по ключу. Таблица может иметь только один кластерный индекс | Основной ключ поиска по диапазону; первичный ключ (PK) в большинстве СУБД создаётся кластерным по умолчанию |
| Некластерный (Non-Clustered) | Отдельная структура со ссылками на строки. Таблица может иметь несколько некластерных индексов | Дополнительные столбцы поиска, фильтрации и join-ключи |
Аналогия для интервью: кластерный индекс — это папки в шкафу, расположенные по алфавиту (данные физически упорядочены). Некластерный индекс — это отдельная записная книжка с именами и номерами полок, где лежит каждая папка.
По алгоритму структуры
| Тип | Алгоритм | Поддерживаемые операции | Когда использовать |
|---|---|---|---|
| B-tree (B+Tree) | Сбалансированное дерево | =, <, >, <=, >=, BETWEEN, LIKE 'val%', ORDER BY | По умолчанию — подходит для большинства задач |
| Hash | Хэш-функция → бакеты | Только = (точное совпадение) | Кэши, справочники, поиск по уникальному ключу; O(1) поиск |
| GIN (Generalized Inverted Index) | Инвертированный индекс | @>, <@, &&, full-text search | Массивы, JSONB, полнотекстовый поиск (PostgreSQL) |
| GiST | Обобщённое дерево поиска | Геоданные, диапазоны, пространственные операции | Геоинформационные системы, IP-диапазоны |
| BRIN (Block Range Index) | Метаданные диапазонов блоков | Диапазонные запросы на больших монотонных данных | Огромные таблицы логов с последовательной вставкой; очень маленький размер |
| Columnstore | Хранение по столбцам | Агрегации и аналитика | DWH, OLAP-нагрузки; до 10x прирост производительности |
| Bitmap | Битовые маски по значениям | Фильтрация столбцов с низкой кардинальностью | Аналитические БД; status, gender, region — столбцы с малым числом уникальных значений |
По составу столбцов
Одностолбцовый (Single-column) — классика, одна колонка.
Составной (Composite / Compound) — несколько столбцов в одном индексе, например (status, created_at). Порядок столбцов имеет критическое значение — подробнее ниже.
Покрывающий (Covering Index) — некластерный индекс, который включает (через INCLUDE) все столбцы, нужные запросу. СУБД не обращается к основной таблице вовсе — index-only scan. Это один из мощнейших приёмов оптимизации.
-- Покрывающий индекс: возвращает job_title и hire_date без lookup в таблицу
CREATE INDEX idx_emp_covering
ON employees (department_id)
INCLUDE (job_title, hire_date);
Частичный (Partial / Filtered) — индексирует только подмножество строк, удовлетворяющих условию WHERE.
-- Индексируем только необработанные заказы (99% строк с 'completed' не трогаем)
CREATE INDEX idx_orders_pending
ON orders (customer_id)
WHERE status = 'pending';
Уникальный (Unique) — гарантирует отсутствие дублей. Одновременно выполняет роль ограничения целостности.
Ключевые концепции, которые спросят на собеседовании
Селективность (Selectivity)
Селективность = отношение уникальных значений к общему числу строк. Чем выше — тем эффективнее индекс сужает выборку.
- Высокая кардинальность → хорошо индексировать:
user_id,email,order_number - Низкая кардинальность → индекс часто бесполезен:
is_active(true/false),gender,status(3–5 значений)
Ловушка на интервью: индекс с низкой кардинальностью оптимизатор может вообще проигнорировать и сделать full scan — это дешевле. Правильный ответ: для низкокардинальных столбцов используем частичный индекс или составной индекс в паре с высококардинальным столбцом.
Правило левого префикса (Leftmost Prefix Rule)
Составной индекс (A, B, C) работает для запросов, которые используют:
AA, BA, B, C
Но не работает для B, C, B, C — без ведущего столбца индекс не используется.
Порядок столбцов в составном индексе:
- Сначала столбцы с условием
=(точное равенство), самые селективные — первыми - Затем столбцы с диапазонными условиями (
>,<,BETWEEN) - В конце — столбцы для
ORDER BYиGROUP BY
-- Запрос: WHERE status = 'active' AND created_at > '2026-01-01' ORDER BY priority
-- Правильно: сначала equality, потом range, потом sort
CREATE INDEX idx_correct ON tasks (status, created_at, priority);
-- Неправильно: range-столбец в начале «сломает» использование status и priority
CREATE INDEX idx_wrong ON tasks (created_at, status, priority);
Read vs Write архитектурный компромисс
Каждый индекс:
- Ускоряет SELECT-запросы
- Замедляет INSERT, UPDATE, DELETE — база обновляет каждый индекс при каждом изменении строки
- Занимает место на диске
Создание одного глобального индекса в распределённых СУБД может снизить производительность записи до 30% от исходной. Восемь локальных индексов в MySQL — до 85%.
Вывод для интервью: индексы нельзя создавать «на всякий случай». Каждый индекс — это осознанное решение.
Когда индекс НЕ поможет (и интервьюер ждёт именно этого)
Понимание ситуаций, где индекс бесполезен или вреден показывает знание и опыт и выделяет кандидата на интервью.
| Ситуация | Почему индекс не сработает | Что делать |
|---|---|---|
LIKE '%keyword%' — wildcard в начале строки | B-tree не может использоваться, так как начало строки неизвестно | Full-text индекс (GIN/FTS) или поисковый движок |
Функция над индексированным столбцом: WHERE YEAR(created_at) = 2026 | Индекс создан на столбец, а не на результат функции | Вычисляемый/функциональный индекс или переписать условие: WHERE created_at BETWEEN '2026-01-01' AND '2026-12-31' |
Низкая кардинальность: WHERE is_deleted = false на таблице, где 98% строк — false | Оптимизатор предпочтёт full scan | Частичный индекс: WHERE is_deleted = false |
| Запрос возвращает большой процент строк таблицы (> 15–20%) | Чтение через индекс + lookup медленнее full scan | Пересмотреть структуру запроса или добавить покрывающий индекс |
| Write-heavy таблица (очередь сообщений, лог событий) | Накладные расходы на обновление индексов критичны | Минимизировать количество индексов; рассмотреть BRIN для append-only таблиц |
| Неиспользуемый индекс | «Мёртвый груз» — только замедляет запись и занимает место | Регулярно мониторить pg_stat_user_indexes / sys.dm_db_index_usage_stats и удалять |
Алгоритм выбора индекса на интервью
Хороший кандидат не называет тип индекса сразу — он задаёт уточняющие вопросы и рассуждает вслух. Вот рабочий алгоритм:
Шаг 1. Зафиксировать нагрузку
- Какой тип нагрузки: OLTP (точечные запросы), OLAP (агрегации), смешанный?
- Каково соотношение read/write? Если write > 70% — индексы надо минимизировать.
- Каков объём таблицы? Для маленьких таблиц (< 1000 строк) индексы почти бесполезны.
Шаг 2. Проанализировать запросы
- Какие условия в
WHERE? → Определяем столбцы-кандидаты - Есть ли
ORDER BY/GROUP BY? → Добавляем в составной индекс - Что возвращает SELECT? → Рассматриваем покрывающий индекс
- Используются ли
JOIN? → Индексируем внешние ключи и join-столбцы
Шаг 3. Оценить кардинальность
- Высокая → простой B-tree индекс
- Низкая, но запрос часто фильтрует конкретное значение → частичный индекс
- Низкая в комбинации с высококардинальным → составной индекс
Шаг 4. Выбрать тип
- Большинство задач → B-tree
- Только точное равенство, высокая нагрузка → Hash
- JSON/массивы/полнотекстовый поиск → GIN
- Геоданные → GiST / SP-GiST
- Огромные append-only таблицы → BRIN
- Аналитика/DWH → Columnstore
Шаг 5. Проверить через планирощик
На интервью обязательно сказать, что индекс проверяется через план выполнения запроса.
-- PostgreSQL
EXPLAIN ANALYZE SELECT * FROM orders WHERE customer_id = 42;
-- SQL Server
SET STATISTICS IO ON;
-- или нажать «Включить план выполнения»
Ищем в плане:
- Index Seek (хорошо) vs Table Scan (плохо)
- Key Lookup / RID Lookup — сигнал добавить покрывающий индекс
rows— сколько строк реально отфильтровал индекс- Using filesort (MySQL) — сигнал пересмотреть порядок столбцов в составном индексе
Типичные вопросы на собеседовании и готовые ответы
«Чем кластерный индекс отличается от некластерного?»
Кластерный индекс определяет физический порядок хранения строк таблицы на диске. Поэтому в таблице может быть только один кластерный индекс. Узлы B-tree индекса содержат сами данные строк. Некластерный индекс — это отдельная структура, узлы которой содержат значения ключа и указатель на строку в таблице (row locator). Таблица может иметь несколько некластерных индексов.
Практическое следствие: при запросе по некластерному индексу СУБД сначала ищет ключ в индексе, а потом делает второй переход (lookup) к основной таблице — это дороже. Покрывающий индекс устраняет необходимость в этом втором переходе.
«Что такое составной индекс и почему важен порядок столбцов?»
Составной индекс - это индекс, который включает в себя несколько столбцов. Данные в нём отсортированы сначала по первому столбцу, затем по второму внутри каждого первого значения — и так далее. Это означает, что индекс (A, B, C) может использоваться для запросов, фильтрующих A, или A и B, или A, B и C. Запрос только по B или только по C индекс задействовать не сможет — это правило левого префикса.
Порядок столбцов: условия на = и самые селективные первыми → range-условия → sort-условия.
«Когда не нужно создавать индекс?»
- Таблица маленькая (full scan дешевле)
- Столбец с очень низкой кардинальностью при отсутствии частичного индекса
- Таблица write-heavy — накладные расходы перевесят пользу
- Индекс уже есть на более широком составном ключе, покрывающем данный столбец как префикс
- Запрос всё равно возвращает большую часть таблицы
«Что такое частичный (partial) индекс и когда его применять?»
Частичный индекс содержит только строки, удовлетворяющие условию WHERE. Он меньше по размеру, быстрее обновляется и даёт высокую эффективность для запросов с постоянным фильтром. Классические сценарии:
- Только активные (не удалённые) записи:
WHERE deleted_at IS NULL - Только необработанные заявки:
WHERE status = 'pending' - Только ненулевые значения опционального поля
«Что покажет планировщик и как вы его читаете?»
Смотрим на тип операции (Index Seek vs Scan vs Table Scan), на реальное число строк после фильтрации, на наличие Key Lookup (сигнал для покрывающего индекса) и на Using filesort / Sort (сигнал пересмотреть порядок в составном индексе). Именно планировщик единственный объективный инструмент проверки гипотезы об индексе.
Антипаттерны, которые выдают отсутствие опыта
- «Поставим индекс на все столбцы» — самая частая ошибка. Чем больше индексов, тем медленнее запись и тем сложнее оптимизатору выбрать нужный.
- Индекс на функцию от столбца —
WHERE UPPER(name) = 'IVAN'не использует индекс наname. Нужен функциональный индекс или пересмотр подхода к хранению данных. - Составной индекс в неправильном порядке — нарушение правила левого префикса, в результате индекс не применяется ни к одному из реальных запросов.
- Индекс на внешний ключ без анализа нагрузки — внешние ключи надо индексировать, но не всегда: если join идёт крайне редко, индекс только замедляет вставку.
- Игнорирование планировщика запросов — создание индексов «на глаз», без проверки плана выполнения запроса.
Системный аналитик, который умеет обосновать выбор типа и состава индекса через бизнес-нагрузку и план выполнения запроса будет заметен на собеседовании и выгодно выделиться среди кандидатов.
Если хотите лучше подготовится к собеседованию приходите на менторинг помогу подготовится Подробнее: /mentoring/.